Engineering Mechanics - KOP: Work and Energy - Discussion
Discussion Forum : KOP: Work and Energy - General Questions (Q.No. 4)
4.
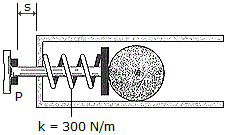
The firing mechanism of a pinball machine consists of a plunger P having a mass of 0.25 kg and a spring of stiffness k = 300 N/m. When s = 0, the spring is compressed 50 mm. If the arm is pulled back such that s = 100 mm and released, determine the speed of the 0.3 kg pinball B just before the plunger strikes the stop, i.e., s = 0. Assume all sufaces of contact to be smooth. The ball moves in the horizontal plane. Note that the ball slides without rolling.
Discussion:
1 comments Page 1 of 1.
Jani Dhruvkumar said:
7 years ago
(1/2)(300)[(0+50)^2]
= (1/2)(300)[(100+50)^2] + (1/2)(.3+.25)(v^2).
V = 3.30m/s.
= (1/2)(300)[(100+50)^2] + (1/2)(.3+.25)(v^2).
V = 3.30m/s.
(1)
Post your comments here:
Quick links
Quantitative Aptitude
Verbal (English)
Reasoning
Programming
Interview
Placement Papers